

دوچرخهسواران منهتن: یک آشنایی با علم داده
علم داده یکی از سودمندترین کاربردهای برنامهنویسی هست. با میانگین حقوق پایه ۱۲۱ هزار دلار در سال، علم داده یکی از پردرآمدترین شاخههای برنامهنویسی و ریاضی هم هست.
در این خواندنی با تحلیل دادههای رفتوآمد دوچرخهسواران در منطقه منهتنِ نیویورک با علم داده آشنا میشویم.
دوره برنامهنویسی ریاضی پیشنیاز این خواندنی هست.
تحلیل داده چیست؟
داده مجموعهای از مشاهدهها از یک پدیده هست.
برای نمونه، بارش باران در شهر تهران را در نظر بگیر. پدیده، بارش باران در شهر تهران هست و مشاهدهها، مقدار بارش در هر روز هست. برای این مثال، داده ما برای یک سال شامل ۳۶۵ عدد هست که هر عدد مقدار بارش در یک روز سال است.
تحلیل داده فرآیند استخراج اطلاعات از داده برای تصمیمگیری هست. مثلا، اداره آب تهران هر سال با تحلیل دادههای بارش و مصرف آب در سالهای گذشته تصمیم میگیرد که سال آینده چقدر از آب سدهای تهران را در هر ماه استفاده کند.
یا مثلا برنامه Google Maps بیشتر از ۲۰ پتابایت (۲۰ میلیون گیگابایت) داده خام ذخیرهشده دارد. با تحلیل این دادهها به رانندگان کمک میکند که برای انتخاب مسیر تصمیمگیری کنند.

صورت مسأله
منهتن یکی از گرانترین مناطق دنیا هست که سازمانها و شرکتهای بسیاری را در خود جای داده است. منهتن چون یک جزیره هست دارای پلهای متعددی هم است.
به دلیل گرانبودن پارکینگ در منهتن، خیلیها برای رفتوآمد به منهتن از دوچرخه استفاده میکنند. چهارتا از پلهای اصلی برای رسیدن به منهتن پلهای بروکلین (Brooklyn)، منهتن (Manhattan)، ویلیامزبرگ (Williamsburg)، و کویینزبرو (Queensboro) هستند.
این چهار پل همه مجهز به یک دستگاههایی هستند که تعداد دوچرخهسواران را هر روز میشمارند و ذخیره میکنند. ما میخواهیم با تحلیل این دادهها، به سوالهای زیر پاسخ بدهیم:
۱. چه روزی شلوغترین روز سال ۲۰۱۶ بود؟
۲. بارش باران و دمای هوا چه تأثیری بر روی تعداد دوچرخهسواران دارند؟
۳. دوچرخهسواران از کدام پل بیشتر از همه استفاده میکنند؟
۴. در کدام روز هفته و ماه سال تعداد دوچرخهسواران از همه بیشتر میشود؟
داده خام
داده خام را ما از سایت شهرداری نیویورک به دست آوردیم. فایلش را از اینجا دانلود کن و در یک فولدر خالی جدید به نام nyc در کامپیوترت ذخیره کن.
فرمت این داده CSV (مخفف Comma-Separated Values) هست که یعنی مقادیر با کاما از هم جدا شدهاند. فایل را با برنامه Notepad باز کن. سطر اول نام متغیرهایی هست که اندازهگیری شدهاند. سطرهای بعد، هر کدام، مقدار این متغیرها برای یک روز هستند.

آمادهسازی محیط توسعه
با پایتون نسخه ۳ در محیط پایچارم برنامهمون را مینویسیم و از ماژولهای زیر هم استفاده میکنیم:
ماژولهای os و csv: برای خواندن فایل CSV و تبدیل آن به یک لیست از دیکشنریها
ماژولهای matplotlib و seaborn: برای رسم نمودارها
نحوه نصب ابزارهای بالا را میتونی در این خواندنی ببینی و انجام بدی.
پس از بازکردن پایچارم، فولدر nyc را برای پروژه انتخاب کن. یک فایل جدید پایتون به نام main هم در داخلش بساز.
اول باید ماژولها را وارد کنیم:
|
1 2 3 4 5 |
# Import libraries import csv import os import matplotlib.pyplot as plt import seaborn as sns |
خواندن و آمادهسازی داده
داده ما شبیه یک جدول مرتب شده و دارای سطر و ستون است. این برای نمونه پنج سطر اول داده هست:

حالا فایل داده را از داخل پایتون میخوانیم و تبدیل به یک لیست از دیکشنریها میکنیم:
|
1 2 3 4 5 6 7 8 9 |
# Read and prepare the data ... here_path = os.path.dirname(os.path.realpath(__file__)) data_file_name = 'nyc_cyclist_crossing_east_river_2016_pylie.csv' data_file_path = os.path.join(here_path, data_file_name) with open(data_file_path) as f: data = [{k: v for k, v in row.items()} for row in csv.DictReader(f)] print(data[0]) |
برنامه بالا ابتدا فایل داده را باز میکند (open) و سپس خطها را یکییکی با روش پیمایش لیست میخواند و به صورت یک دیکشنری ذخیره میکند. هر دیکشنری یک سطر از فایل CSV هست.
آدرس فایل داده را میتونی مستقیم هم از کامپیوترت کپی و در data_file_path بگذاری.
پایتون همه مقادیر را با نوع رشته (string) میخواند. پس اونهایی که باید نوعشون عدد باشد را به integer یا float تبدیل کنیم. اول کلید اونها را در یک لیست مینویسیم و بعد با یک پیمایش، یکییکی به نوع مورد نظر تبدیل میکنیم:
|
1 2 3 4 5 6 7 |
# Convert numeral values to integer and float int_keys = ['Year', 'Day', 'Brooklyn', 'Manhattan', 'Williamsburg', 'Queensboro', 'Total'] data = [dict([a, int(x)] if a in int_keys else [a, x] for a, x in d.items()) for d in data] float_keys = ['Temperature', 'Precipitation'] data = [dict([a, float(x)] if a in float_keys else [a, x] for a, x in d.items()) for d in data] print(data[0]) |
شلوغترین روز سال
برای این کار کافیه لیست دیکشنریها را به ترتیب کلید Total از بزرگ به کوچک مرتب کنیم:
|
1 2 3 4 |
# Busiest days of the year ... data_total_sorted = sorted(data, key=lambda k: k['Total'], reverse=True) print(data_total_sorted[0]) |
پس شلوغترین روز سال ۲۰۱۶ چه روزی بوده؟ در این روز در مجموع چند دوچرخهسوار از پلها رد شدند؟ روزهای شلوغ بعد چطور؟
تأثیر بارش
میخواهیم ببینیم تعداد دوچرخهسواران در روزهای بارانی (rainy) چقدر با روزهای خشک (dry) فرق داره.
داده ما دارای یک کلید به نام Precipitation هست که مقدار بارش به میلیمتر در اون روز هست. پس اگر صفر باشه یعنی اون روز بارون نیومده بوده.
باید روزهای بارانی و غیربارانی را جدا کنیم و میانگین تعداد دوچرخهسواران در هر کدوم را حساب کنیم. میانگین یعنی مجموع کل دوچرخهسواران در روزهای بارانی را حساب کنیم و بعد تقسیم بر تعداد کل روزهای بارانی کنیم.
این میشه برنامه ما:
|
1 2 3 4 5 6 7 8 |
# Rain ... data_rainy = [d for d in data if d['Precipitation'] > 0] data_rainy_totals_list = [d['Total'] for d in data_rainy] rainy_average = sum(data_rainy_totals_list) / len(data_rainy_totals_list) data_dry = [d for d in data if d['Precipitation'] <= 0] data_dry_totals_list = [d['Total'] for d in data_dry] dry_average = sum(data_dry_totals_list) / len(data_dry_totals_list) |
تابع sum و len به ترتیب مجموع و اندازه لیست را به دست میارند.
اطلاعات را وقتی با نمودار نمایش بدیم خیلی گویاتر میشوند.
بیا با استفاده از تابع barplot در ماژول seaborn میانگینهای روزهای بارانی و خشک را که به دست آوردیم را رسم کنیم:
|
1 2 3 4 |
# Plot ... plt.figure() sns.barplot(x=['Rainy', 'Dry'], y=[rainy_average, dry_average]) plt.show() |

تأثیر دمای هوا
داده ما دارای یک کلید به نام Temperature هست که دمای هوا به سانتیگراد در اون روز هست.
برنامهای بنویس که روزهای سرد و گرم را از هم جدا کند و میانگین تعداد دوچرخهسواران در هر کدوم را حساب کند. مرز سرما را ۱۰ درجه بگذار. نمودارش را هم رسم کن.
در روزهای سرد میانگین تعداد دوچرخهسواران بیشتر هست یا کمتر؟ چقدر؟ در چه مرزی از دما این دو تقریبا برابر میشوند؟
شلوغترین پلها
با یک حلقه بر روی لیست پلها میتونیم تعداد دوچرخهسواران برای هر کدوم را جدا کنیم. و بعدش میانگین را حساب و در یک لیست دیکشنری جدید ذخیره کنیم.
اینطور:
|
1 2 3 4 5 6 7 8 9 10 11 |
# Bridges ... bridges = ['Brooklyn', 'Manhattan', 'Williamsburg', 'Queensboro'] bridges_average = [] for bridge in bridges: crossings_bridge = [d[bridge] for d in data] average = sum(crossings_bridge) / len(crossings_bridge) bridges_average.append(dict({'bridge': bridge, 'average': average})) plt.figure() sns.barplot(x=[d['bridge'] for d in bridges_average], y=[d['average'] for d in bridges_average]) plt.show() |

کدام پل بیشترین ترافیک دوچرخهسواران را داره؟ کدام یک کمترین؟
شلوغترین روز هفته
اول یک لیست از روزهای هفته درست میکنیم و سپس یک حلقه روی آنها مینویسیم. روزهایی که اون روز هفته هستند را از دادهمون جدا و میانگین مجموع دوچرخهسواران را براش حساب میکنیم:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# Days of week ... weekdays = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday'] weekdays_average = [] for weekday in weekdays: data_weekday = [d for d in data if d['Weekday'] == weekday] crossings_weekday = [d['Total'] for d in data_weekday] average = sum(crossings_weekday) / len(crossings_weekday) weekdays_average.append(dict({'weekday': weekday, 'average': average})) plt.figure() sns.barplot(x=[d['weekday'] for d in weekdays_average], y=[d['average'] for d in weekdays_average]) plt.show() |
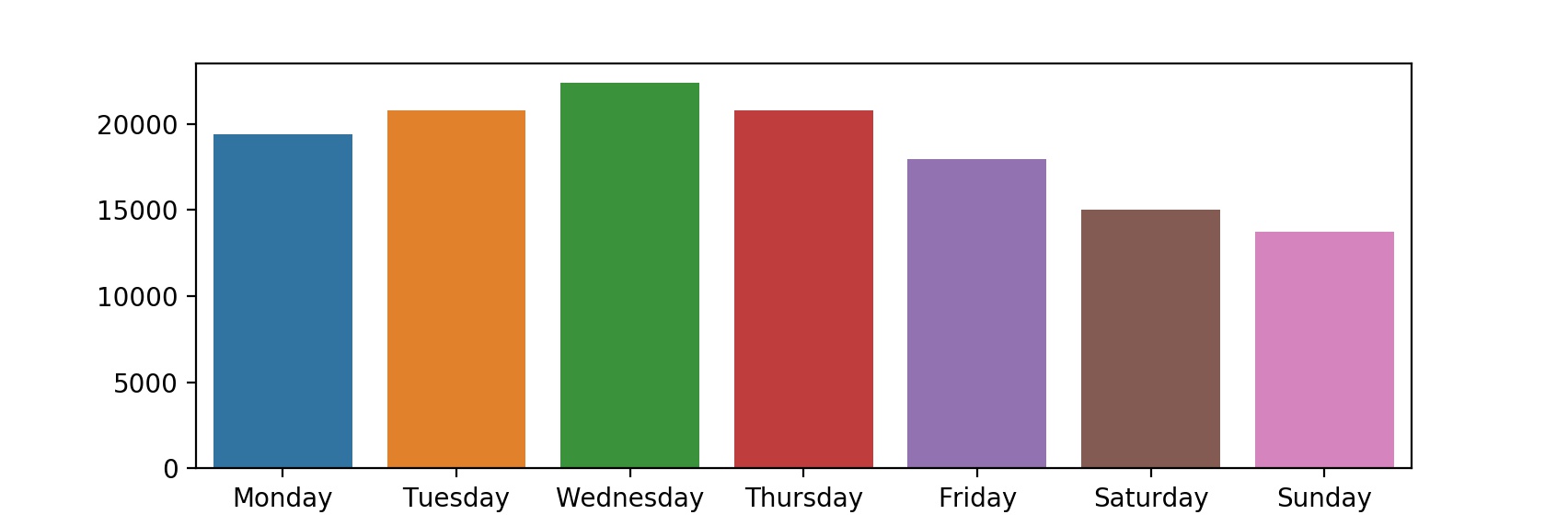
در منهتن روزهای شنبه و یکشنبه آخر هفته و تعطیل هستند. در روزهای کاری دوچرخهسواران بیشتر هست یا تعطیل؟ جواب این سوال به ما میگه که هدف دوچرخهسواران بیشتر تفریحی هست یا کاری.
شلوغترین ماه سال
مثل برنامه شلوغترین روز هفته این را خودت بنویس. این لیست ماههایی هست که در داده ما هست:
|
1 2 |
# Months ... months = ['Apr' 'May' 'Jun' 'Jul' 'Aug' 'Sep' 'Oct'] |
شلوغترین ماه کدام هست؟
فایل پایتون همه برنامههای بالا را میتونی از اینجا دانلود کنی.
ادامه
امروز با برنامهنویسی تونستیم از یک مجموعه از اعداد اطلاعات کاربردی و جالبی را استخراج کنیم.
برنامهنویسان در همه شرکتهای بزرگ دنیا روزانه هزاران تا میلیونها مجموعه داده گوناگون را تحلیل میکنند تا اطلاعاتی ارزشمند را استخراج کنند. از دادههای پزشکی برای تشخیص سرطان گرفته تا دادههای ستارهشناسی برای کشف سیارههای جدید.
پایتون ماژولهایی تخصصی مثل Pandas را هم داره که میتونی برای ادامه یاد بگیری.
اگر موضوع خاصی را هم برای خواندنیهای آینده دوست داشتی پایین در بخش نظرها بنویس.
نظرات
عرفان
سلام لطفا در رابطه با بازی سازی و رابط کاربری آموزش یا خواندنی بزارید